



- @stub.function()
+ @stub.function(gpu="T4")
def f(i):
return i * iCost-effective PyTorch model inference by utilizing Modal.com
How hard is it to deploy pretrained models on GPUs without tons of YAML files and unmanaged instances?
(Disclaimer: This is not a paid endorsement and I have no affiliation with Modal Labs.)
A startup recently asked me to help them design an infrastructure where they can:
run pre-trained PyTorch model on some inputs, such that the execution happens after some customer actions, but shouldn’t last more than an hour
try to avoid managing their own long-running GPU instances
be able to re-deploy newer versions of the model and monitor if and when the model crashes
A lot of their infrastructure was hosted on AWS: S3 and DynamoDB for data, Cognito for authentication, but when it came to inference they were confused. A developer had built some prototypes with Lambda functions + SageMaker — the advertised solution for ML deployments, and it had some issues: Lambda execution time is limited at 15 minutes and configuring SageMaker’s environment became a messy pipeline which they couldn’t maintain1. A lot of the SageMaker models that worked had to run on a CPU. The SageMaker examples repository contains amazon-sagemaker-examples/tree/main/inference which is full of empty folders and ipynb notebooks with 404 links.
As a startup, they were fine with taking a risk of moving the ML inference to any platform2 (even platforms that are startups themselves) as long as they can get PyTorch running ASAP and the execution price is okay.
I already knew that people rent their GPUs on vast.ai at low rates, but even if the GPU owners signed their data processing contract, no one liked the idea of sending user data to hardware managed by strangers. I ran some quick Hacker News, Reddit, Google searches for cheap GPU inference and stumbled upon a comment mentioning Modal.com so I decided to check it out.
The pricing page was very clear and concise. As of the time of writing, it looks like this:
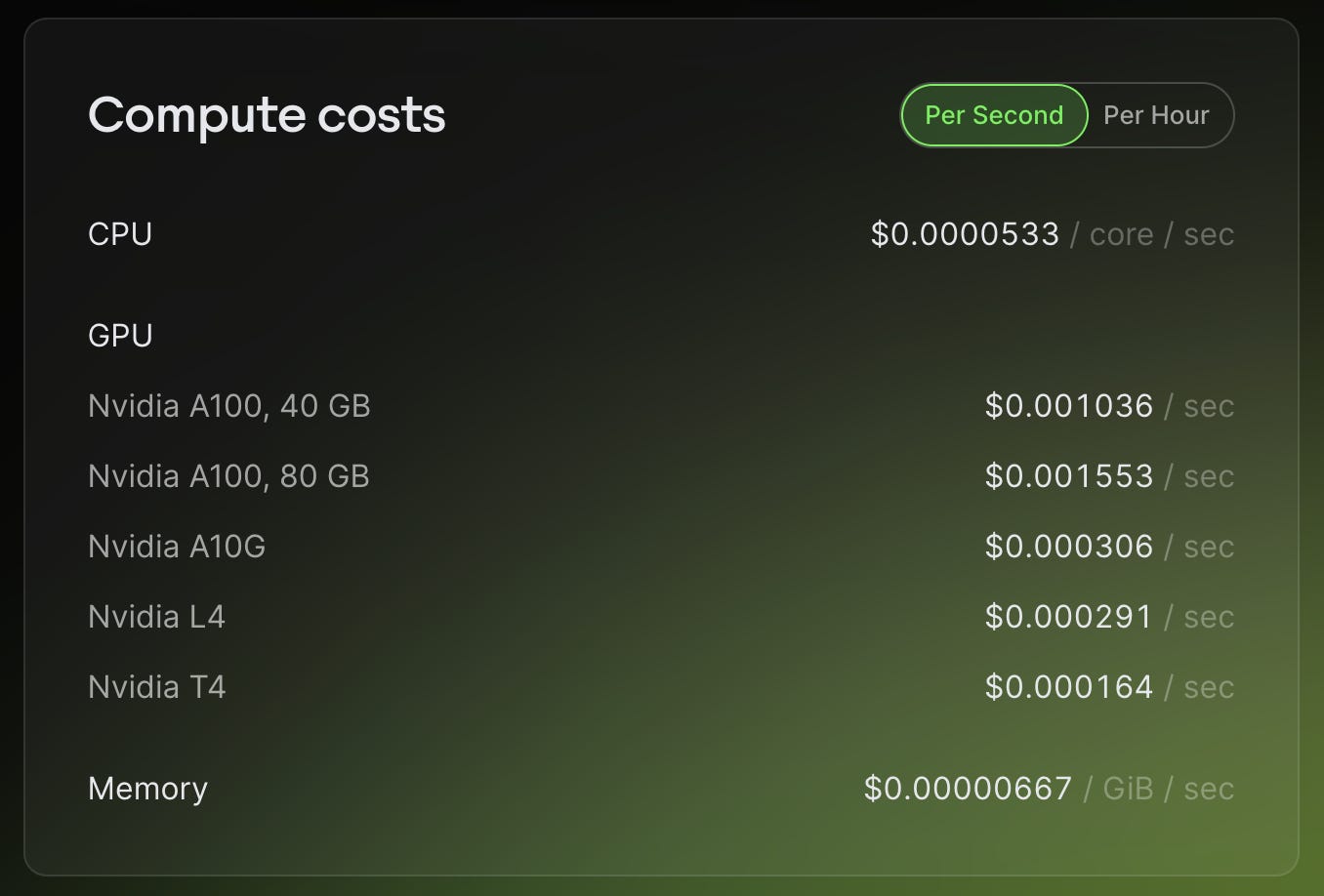
At first glance it's good, so I decided to compare them with AWS. A g4dn.xlarge would correspond to NVIDIA T4 and AWS would charge $0.000146/s while Modal is at $0.000164/s which is a 12% margin (same for hourly rates). That’s reasonable for us - as long as Modal helps us deploy and monitor our model without hassle.
By the way, if you haven’t run models in production and want to understand ML inference economics in practice, here’s an example: running OpenAI’s speech-to-text model (Whisper Large) given a 5 minute English audio input on an NVIDIA T4 would take around 30 seconds. That means a single Whisper call can cost $0.00438.
So I did the well-marketed pip install modal one-liner and logged in with a fresh account. It doesn’t require a credit card by default (yet?) and I got $30 free credit which could power our use for quite some time. Squaring an integer on a remote CPU is simple:
import modal
stub = modal.Stub("fiki-demo")
@stub.function()
def f(i):
return i * i
@stub.local_entrypoint()
def main():
# Call f locally
print(f.local(1000))
# Call f on Modal's cloud CPU
print(f.remote(1000))
Just do modal run yourfile.py and it works. So how do I attach a GPU? Turns out it’s just a matter of editing the decorator:
And how do we ship dependencies like ffmpeg, our AWS secrets, install PyTorch and the pretrained model? It’s quite simple actually. Modal builds Docker images with your code attached, and you have full control over the Dockerfile - scroll to the bottom of the post for an example.
In addition, once you like how model run yourfile.py works, you can deploy your model to production and generate a REST API. The dashboard let’s you see some nice stats (as well as build logs, runtime logs, etc) and billing info.


A model with CUDA, torch, ffmpeg running on T4 cloud, assuming you have a local Python package with myapp/__init__.py and a do_something() model would look like this:
import modal
from modal import (
Image,
Mount,
Secret,
method,
)
image = (
Image.from_registry(
"pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel",
)
.pip_install(
"openai==0.27.2"
)
.apt_install("ffmpeg")
)
stub = modal.Stub(
"fiki-demo",
image=image,
secrets=[Secret.from_name("prod")],
mounts=[
Mount.from_local_python_packages("myapp")
],
)
@stub.cls(
timeout=80000,
gpu="T4"
)
class DiarModel:
@method()
def detect(self, data: bytes):
import torch
print("Is CUDA available:", torch.cuda.is_available())
import myapp
return myapp.do_something(data)
A call is just a matter of DiarModel().detect.remote(data) and deploying from CLI is just modal deploy yourfile.py.
If you can design functions that return JSON serializable data then you can also wrap them with @modal.web_endpoint(method="POST")and your deployment tab will show you the appropriate endpoint URL. Note: I haven’t checked the pricing on REST API bandwidth - if you have more information, please send me a message or comment: is it better to host big blobs on S3 or return them directly?
In conclusion, it’s been a pleasant surprise. At a 12% margin over raw AWS resources, you get a very nice development experience: a well designed CLI, dashboard, Google Colab-like responsiveness and a REST API (that boots GPU code within milliseconds) which you can use to get ML output.
It does seem like they are a young Series A company, which depending on your risk-aversion could mean they are not a suitable choice for you. Their status page indicates they utilize Google Cloud Platform, AWS and Oracle Cloud in order to power the code execution and they have >99.9% uptime so far:

I wish them luck and hope their platform stays developer-focused and reliable.
1
Here’s how even the simplest SageMaker GPU configuration looks like: https://github.com/aws/amazon-sagemaker-examples/blob/main/sagemaker-inference-deployment-guardrails/Update-SageMaker-Inference-endpoint-using-rolling-deployment.ipynb … and this doesn’t include all the S3+build configs to ship a pretrained model.
2
Although giving up on AWS SageMaker was a good idea, before completely giving up on AWS we should have considered raw AWS Elastic Containers with a GPU attached. I’m assuming that’s one of the ways Modal manages to run models internally.
Re: pricing. I think you're comparing Modal's GPU price (without cpu and mem) with AWS GPU+CPU+MEM price
Thanks for writing this, it was a great read. What are some things you think Modal is still lacking?